Moin,
This shortcut was one of the first I made with Browser Actions because I loved the fact that I could now use Browser Actions to create a shortcut that would work with all supported browsers without any tweaking. This is a simple one that combines Browser Actions and Actions for Obsidian to copy any selection from a browser window, add the current date and title/link, and save it all to an Obsidian note where such snippets are collected. Nevertheless, it may inspire you to do similar or more sophisticated things. I would love to see some more showcases of what can be done with Browser Actions, especially in the area of website manipulation.
On the Mac, I was unfortunately unable to extract the “formatted text” of the copied selection and convert it to Markdown using the built-in features of the Shortcuts application. Therefore, I had to develop a JavaScript routine together with ChatGPT4 to do this job. That part is not optimal and does not convert all HTML markup to Markdown, but is sufficient for my purposes.
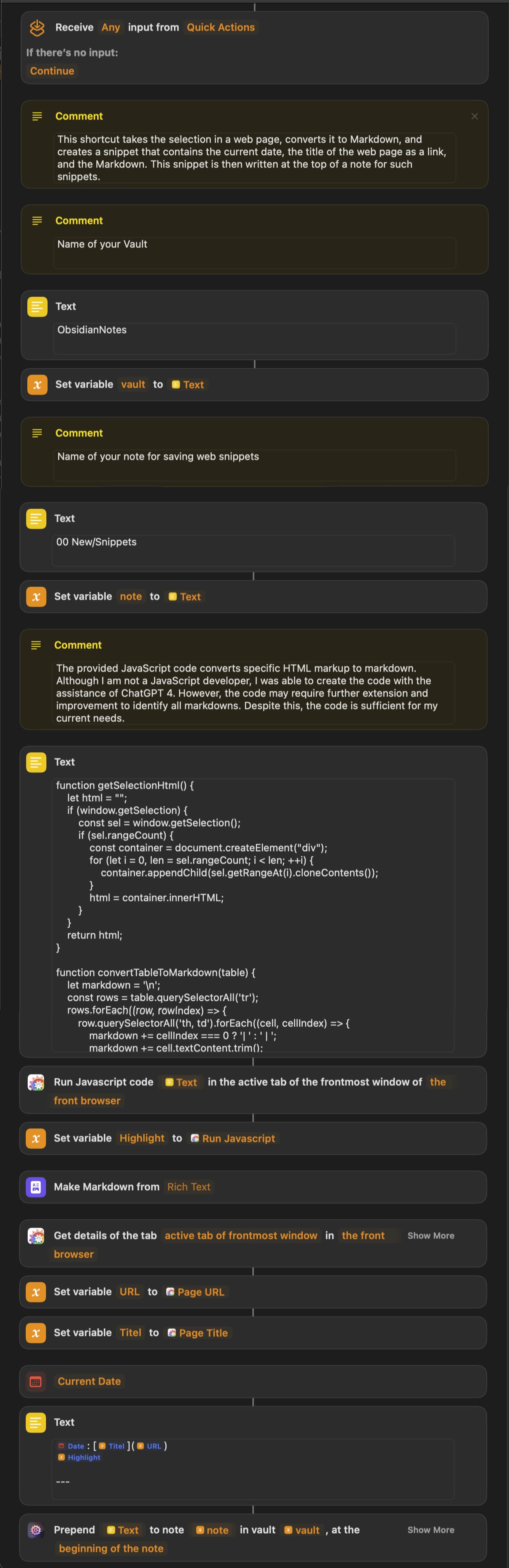
For the shortcut, I use two actions from the Browser Action extension, Run Javascript, to execute the JavaScript code in the current browser window. The result, the converted text, is then written into the Highlight variable. After that, the Get Details of Tab… action collects the URL and the title of the web page which then are written into the corresponding variables. After that the snippet text will be assembled and written to the top of the snippet note with the AFO action Prepend Text To A Note.
In the details of the shortcut, I selected the options Pin to Menu Bar, Use as Quick Action and defined a shortcut under Run with. Now I can select a text in a browser window and capture it together with the current date, URL/title with a keystroke or a click in the menu in an Obsidian note.
Here is the shortcut:
And here is the JavaScript Code:
/**
* JavaScript script for converting a selection in the browser to Markdown format.
* This script extracts the HTML content of the current selection,
* processes various HTML elements (such as paragraphs, headings, links, lists, and tables)
* and converts them into the corresponding Markdown formatting.
* Created by ChatGPT.
*/
// Function to extract the HTML code of the current selection in the browser
function getSelectionHtml() {
let html = "";
if (window.getSelection) {
const sel = window.getSelection();
if (sel.rangeCount) {
const container = document.createElement("div");
for (let i = 0, len = sel.rangeCount; i < len; ++i) {
container.appendChild(sel.getRangeAt(i).cloneContents());
}
html = container.innerHTML;
}
}
return html;
}
// Function to convert an HTML table to Markdown format
function convertTableToMarkdown(table) {
let markdown = '\n';
const rows = table.querySelectorAll('tr');
rows.forEach((row, rowIndex) => {
row.querySelectorAll('th, td').forEach((cell, cellIndex) => {
markdown += cellIndex === 0 ? '| ' : ' | ';
markdown += cell.textContent.trim();
});
markdown += ' |\n';
// Separator line for the table header
if (rowIndex === 0 && table.querySelectorAll('th').length) {
row.querySelectorAll('th').forEach((_, cellIndex) => {
markdown += cellIndex === 0 ? '| ---' : ' | ---';
});
markdown += ' |\n';
}
});
return markdown + '\n';
}
// Function to convert HTML lists (ul, ol) to Markdown lists
function convertListToMarkdown(list, isOrdered) {
let markdown = '\n';
list.querySelectorAll('li').forEach(li => {
markdown += (isOrdered ? '1. ' : '- ') + li.textContent.trim() + '\n';
});
return markdown + '\n';
}
// Function for converting individual HTML elements to Markdown
function convertNode(node) {
if (node.nodeType === Node.TEXT_NODE) {
return node.nodeValue;
}
let markdown = '';
// Conversion based on tag type
switch (node.tagName) {
case 'H1': case 'H2': case 'H3': case 'H4': case 'H5': case 'H6':
const level = node.tagName.charAt(1);
const content = node.querySelector('a') ?
'[' + node.textContent.trim() + '](' + node.querySelector('a').href + ')' :
node.textContent.trim();
markdown += '\n' + '#'.repeat(level) + ' ' + content + '\n';
break;
case 'P':
markdown += node.innerText.trim() + '\n\n';
break;
case 'A':
if (node.parentNode && !['H1', 'H2', 'H3', 'H4', 'H5', 'H6'].includes(node.parentNode.tagName)) {
markdown += '[' + node.textContent.trim() + '](' + node.href + ')';
}
break;
case 'UL':
markdown += convertListToMarkdown(node, false);
break;
case 'OL':
markdown += convertListToMarkdown(node, true);
break;
case 'TABLE':
markdown += convertTableToMarkdown(node);
break;
case 'CODE':
markdown += '`' + node.textContent.trim() + '`';
break;
case 'PRE':
markdown += '\n```\n' + node.textContent.trim() + '\n```\n';
break;
default:
if (node.childNodes.length > 0) {
node.childNodes.forEach(childNode => {
markdown += convertNode(childNode);
});
}
break;
}
return markdown;
}
// Main function to convert the HTML content of the selection to Markdown
function convertHtmlToMarkdown(html) {
const doc = new DOMParser().parseFromString(html, 'text/html');
let markdown = '';
doc.body.childNodes.forEach(node => {
markdown += convertNode(node);
});
return markdown.trim();
}
// Main script part that executes the conversion and returns the result as a list
function main() {
const html = getSelectionHtml();
const markdown = html ? convertHtmlToMarkdown(html) : '';
return [markdown]; // Return the result as a list
}
// Execute the main script and return the result
return main();
Have fun,
Leif